0x00 数据结构定义
树是一种经常用到的数据结构,用来模拟具有树状结构性质的数据集合。树里的每一个节点有一个根植和一个包含所有子节点的列表。从图的观点来看,树也可视为一个拥有N个节点和N-1条边的一个有向无环图。
在计算机科学中,二叉树是每个结点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。
一棵深度为k,且有2^k-1个结点的二叉树,称为满二叉树。这种树的特点是每一层上的结点数都是最大结点数。而在一棵二叉树中,除最后一层外,若其余层都是满的,并且或者最后一层是满的,或者是在右边缺少连续若干结点,则此二叉树为完全二叉树。具有n个结点的完全二叉树的深度为floor(log2n)+1。深度为k的完全二叉树,至少有2^k-1个叶子结点,至多有2^k-1个结点。
本篇博客中,为了方便说明,我们将树的每个节点定义为如下类:
1 | public class TreeNode{ |
树结构的遍历可以分成深度优先搜索(Depth First Search, DFS)和广度优先搜索(Breadth First Search, BFS )。下面我们结合相关题目分别进行介绍。
0x01 DFS
深度优先搜索从根节点开始,通过迭代或递归的方法找到不存在子节点的叶子节点,并添加到结果数组中。DFS算法包括前序遍历,中序遍历和后序遍历三种遍历方法,与BFS不同的是,深度优先搜索按照一定的路径从最高层访问到最低层,然后再返回到适当层进行深度优先搜索,而不是按照层序遍历顺序。
前序遍历
前序遍历首先访问根节点,然后遍历左子树,最后遍历右子树。
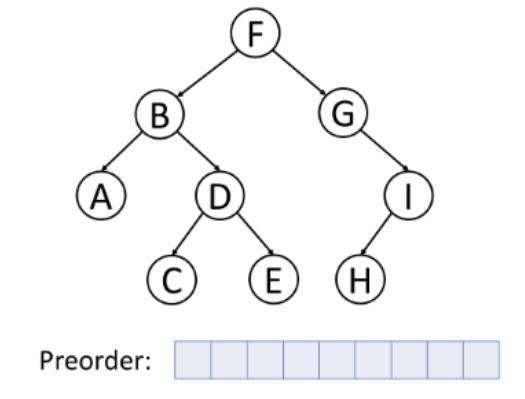
上图中的树采用前序遍历得到的顺序为:F->B->A->D->C->E->G->I->H。
我们通过题目来进行二叉树前序遍历代码的编写与解析。
题目链接
144.Binary Tree Preorder Traversal
题目描述

迭代法
二叉树的前序遍历顺序为:root->left tree->right tree,我们维护两个链表,一个整型链表用于存储最终的输出结果,另一个节点类型的链表用作暂存中间值的栈。如果输入的数组为空则直接返回空链表,否则将根节点压入栈。这里我们调用两个链表特有的方法LinkedList.isEmpty()和LinkedList.pollLast()。第一个方法检查链表,如果为空则返回true,否则返回false。第二个方法将链表作为栈,实现LIFO,即后压入栈的元素先从栈中弹出。
在while循环中不停检查stack链表是否为空,若为空则返回result链表,否则进入循环体。循环体内部首先进行stack链表的弹栈,并将该节点的值存入result链表。然后进行左右节点的压栈,因为我们调用pollLast()方法,所以需要先将右节点压栈,再将左节点压栈,从而实现先左后右的前序遍历。
代码如下:
1 | class Solution { |
递归法
相较于迭代法,递归法使用过程中不需要定义 作为栈的节点类型的链表,从而不需要考虑压栈顺序问题。使用递归法我们首先定义一个void类型的递归函数,该函数接收TreeNode root, List<Integer> result这两个参数。由于前序遍历的顺序为root->left->right,于是当传入节点不为空值时,先将该节点的值加入result数组,然后分别判断递归左子树和右子树即可。
代码如下:
1 | class Solution{ |
莫里斯遍历
算法思路如下:
从当前节点向下访问先序遍历的前驱节点,每个前驱节点都恰好被访问两次。
首先从当前节点开始,向左孩子走一步然后沿着右孩子一直向下访问,直到到达一个叶子节点(当前节点的中序遍历前驱节点),所以我们更新输出并建立一条伪边
predecessor.right = root更新这个前驱的下一个点。如果我们第二次访问到前驱节点,由于已经指向了当前节点,我们移除伪边并移动到下一个顶点。如果第一步向左的移动不存在,就直接更新输出并向右移动。
Java代码如下:
1 | class Solution{ |
中序遍历
中序遍历首先遍历左子树,然后访问根节点,最后遍历右子树。
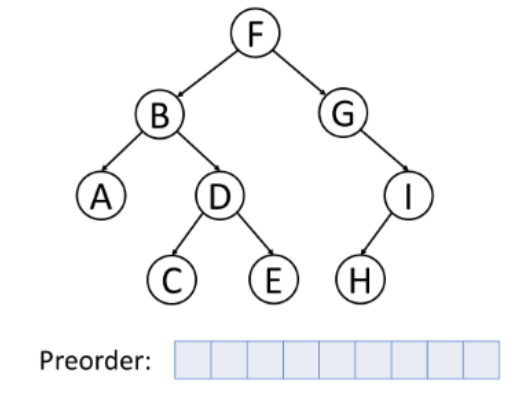
上图中的树采用中序遍历得到的顺序为:A->B->C->D->E->F->G->H->I。通常来说,对于二叉搜索树,我们可以通过中序遍历得到一个递增的有序序列。
我们通过题目来了解二叉树中序遍历的代码编写方式。
题目链接
94.Binary Tree Inorder Traversal
题目描述

迭代法
迭代法需要初始化并维护一个栈stack和一个数组result,由于需要用到栈类的pop()和push()方法,所以必须初始化Stack类。我们首先初始化一个TreeNode类型的变量来承接root输入,当初始节点不为空且栈不为空时,我们不断向栈内压入当前节点的左节点,同时令current = current.left。到达第一个左节点为空的节点时,将该节点弹出并将其值加入result数组中,然后令current = current.right,从而实现left->root->right的中序遍历。
代码如下:
1 | class Solution { |
递归法
递归法不需要使用栈类,直接构造void返回类型的函数,输入为TreeNode root和List<Integer> result两个参数。由于中序遍历的顺序是left->root->right,故当根节点不为空时,先进行左子树递归,再将该节点的值加入result数组中,最后进行右子树的递归。
代码如下:
1 | class Solution { |
莫里斯遍历
本方法使用一种称为线索二叉树的新型数据结构,方法如下:
- 将当前节点current初始化为根节点
- 当current不为空时,进入while循环
- 若current没有左子节点
- 将current添加到输出
- 进入右子树,即令
current = current.right- 否则
- 在current的左子树中,令current成为最右侧节点的右子节点
- 进入左子树,即令
current = current.left
代码如下:
1 | class Solution{ |
后序遍历
后序遍历首先遍历左子树,然后遍历右子树,最后访问树的根节点。
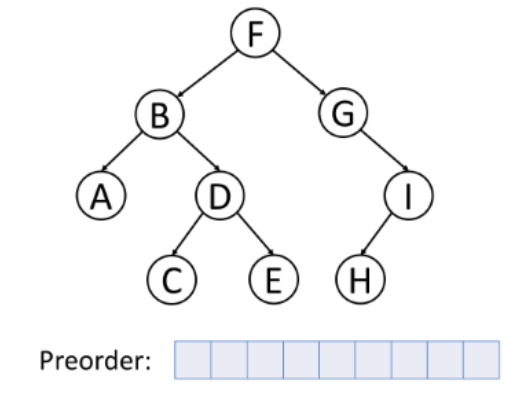
上图中的树采用后序遍历得到的顺序为:A->C->E->D->B->H->I->G->F。当删除树中的节点时,删除过程将按照后序遍历的顺序进行。也就是说,在删除一个节点之前,必须先删除其左节点和右节点,然后再删除其本身。后序在数学表达式中被广泛使用。
同样通过一个题目来介绍后序遍历的几种代码编写方式。
题目链接
145.Binary Tree Postorder Traversal
题目描述

迭代法
使用迭代法需要维护两个整型链表分别用作结果和临时数据栈。当根节点为空时,直接返回result数组,否则将该节点压栈。当栈非空时进入循环,由于栈具有LIFO的特点,所以我们将栈中弹出的元素加入到链表的头部。具体来说,我们先压入root节点,然后将其弹出并放入result数组中。然后按照left->right的顺序压栈,随后按相反顺序弹出,再将弹出的节点插入到result链表的头部,最终得到的结果为left->right->root。
代码如下:
1 | class Solution{ |
递归法
递归法不需要定义多余的栈结构,只使用一个存放最终结果的result链表即可。需要定义一个void类型的输入为TreeNode root和List<Integer> result的函数作为递归函数。由于后序遍历的顺序为left->right->root,故递归函数中先完成左子树递归,再进行右子树递归,最后将根节点的值存入result数组中。特别注意的是在进入左右递归前需要检查所给的root节点是否为空,否则当测试输入为[]时会出现空指针异常。
0x02 BFS
广度优先搜索是一种广泛运用在树或图这类数据结构中,遍历或搜索的算法。该算法从一个根节点开始,首先访问节点本身,然后遍历它的相邻节点,其次遍历它的二级邻节点、三级邻节点,以此类推。
当我们在树中进行广度优先搜索时,我们访问的节点顺序是按照层序遍历顺序的。
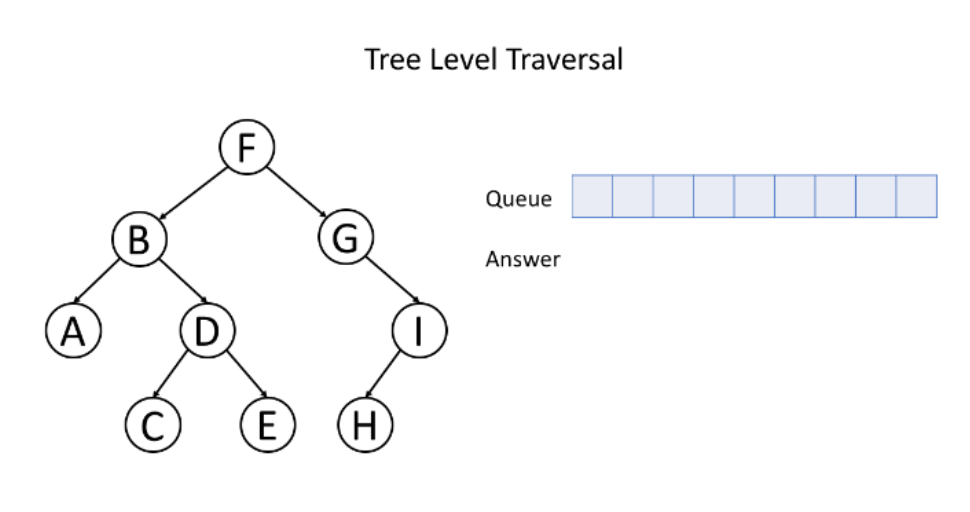
上图中的树采用层序遍历得到的结果为[[F],[B,G],[A,D,I],[C,E,H]]。
通过一道题目来了解层序遍历。
题目链接
102.Binary Tree Level Order Traversal
题目描述

迭代法
迭代法需要定义List<List<Integer>> result和Queue<TreeNode> queue两个结构,前者用来存放最终的返回结果,后者用来作为临时存储队列。队列结构满足FIFO原则,在Java中可以使用Queue接口中的LinkedList实现。
我们定义第0层只包含根节点root,算法实现如下:
Step1: 初始化队列只包含一个节点
root和层次编号0:level = 0。Step2: 当队列非空的时候:
- 在输出结果result中插入一个空列表,用于存储当前层的数据;
- 计算当前层的元素个数——等于队列的长度;
- 将这些元素从队列中弹出(
Queue.remove()函数返回队列的首部元素),并加入到result当前层的空列表中;- 将他们的孩子节点作为下一层压入队列中;
- 使用
level++进入下一层。
代码如下:
1 | class Solution { |
递归法
使用递归的方法,首先开辟一个用于存放结果的二维列表,然后构造void类型的递归函数,下面来详细讲解递归函数的内部。代码如下:
1 | public void helper(TreeNode root, int level){ |
递归函数helper的输入为TreeNode root和int level。首先比较结果数组开辟的现有长度和层数level,如果二者相等则开辟一个新数组用于存放当前层节点的值,这种开辟方法与初始递归时设定level = 0对应。将当前层的节点存入对应的数组后(get()函数实现根据index返回对应数组的功能)继续进行其左右孩子的递归,每次递归令level++。
该方法的本质是DFS,只不过每次递归过程中使用level参数确定遍历节点的存入层数。
完整代码如下:
1 | class Solution { |
0x03 模板总结
迭代法
使用迭代法进行解题时一般需要定义两个List类型的列表,一个用来存放最终的结果,一个用作临时数据栈。由于Queue结构和Stack结构均具有LinkedList对应的接口,所以我们可以使用这两个数据结构更加方便地完成压栈弹栈操作。
迭代法操作过程中的重难点就是压栈弹栈的顺序问题。
- 前序遍历:该遍历方法的顺序是
root->left->right,我们在进行子节点弹栈过程中使用方法LinkedList.pollLast(),对应LIFO原则,所以需要先将根节点弹出,再按照先右节点后左节点的顺序压栈,以便节点进入结果链表的顺序为先左后右。 - 中序遍历:该遍历方法的顺序是
left->root->right,我们需要不断搜索根节点的左子树并使用Stack.push()将其压栈。当搜索路径到达叶子节点时,我们将上一次压入的左节点使用Stack.pop()弹栈并加入结果队列,再将其父节点(root)加入结果队列,最后将root定位为父节点的右孩子,重复上述过程。 - 后序遍历:该遍历方法的顺序是
left->right->root,该遍历方法可以理解为前序遍历的逆序。我们使用LinkedList.pollLast()进行弹栈,对应使用LinkedList.addFirst()将弹出节点加入结果链表中从而实现逆序。 - BFS:该遍历方法使用临时数据栈储存一层中所有的节点,每次改变层数时需要完成两件事情:
- 将临时数据栈中的所有节点使用
Queue.remove()方法弹出,并加入到结果数组中; - 将该层节点的所有子节点全部压入临时数据栈,方便检索到下层时弹出。
- 将临时数据栈中的所有节点使用
解决上述问题之后,迭代法就变得更加容易理解和操作,现总结可用模板如下:
1 | class Solution { |
递归法
与迭代法不同的是,递归法只需要定义一个用来存储最终结果的结果链表,该方法的核心为递归函数的设计。
对于DFS,递归函数原型可以抽象为void helper(TreeNode root, List<Type> result);而对于BFS,递归函数原型则抽象为void helper(TreeNode root, int level)。递归函数内部主要由三部分组成(BFS还需要开辟新数组):向结果数组中加入节点,递归左子树,递归右子树。我们需要根据遍历的顺序来决定这三部分的合理顺序。模板如下:
1 | class Solution { |
莫里斯遍历
参考文章:莫里斯遍历
0x04 复杂度分析
迭代法
- 时间复杂度:访问每个节点恰好一次,时间复杂度为
O(N),其中 N 是节点的个数,也就是树的大小。 - 空间复杂度:取决于树的结构,最坏情况存储整棵树,因此空间复杂度是
O(N)。
递归法
- 时间复杂度:
O(n)。递归函数 T(n) = 2 \cdot T(n/2)+1T(n)=2⋅T(n/2)+1。 - 空间复杂度:最坏情况下需要空间
O(n),平均情况为O(log n)。
莫里斯遍历
- 时间复杂度:
O(n)。一棵n个节点的二叉树只有n-1条边,每条边只可能使用2次,一次是定位节点,一次是找前驱节点,所以找到所有节点的前驱节点只需要0(n)时间,故时间复杂度为O(n)。 - 空间复杂度:
O(n),使用了长度为n的数组。
